前言
这几个星期在实验室里的任务是对OpenCV源码里某部分代码使用NEON指令集进行优化,在实际操作的过程中对OpenCV环境的配置、NEON指令集、OpenCV源码都有了一定的理解,在这里将所学到的知识分享出来。
一、NEON指令集
1、概念
NEON是ARM架构下的一种优化的指令集,主要是为了实现SIMD(Single Instruction Multiple Data,单指令多数据流),简单来说就是将多个操作数打包在大型寄存器中、在一条指令下同时操作多个操作数的指令集。在处理一些简单、重复性高的算法的时候,可以并行处理,大大提高效率。
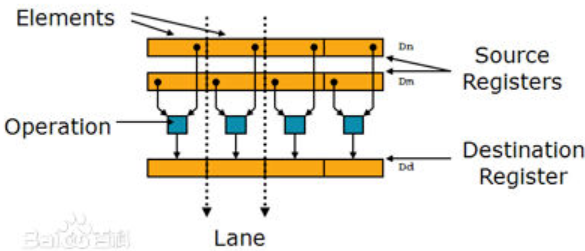
2、数据类型、基本操作
为了更加直观地理解NEON指令集的功能,我们先介绍几个NEON的基本数据类型与操作函数,然后给出一个简单的例子,说明NEON是如何进行性能优化的。
数据类型:
NEON的数据类型遵循以下的命名格式:type size x num _t ,其中:
- type:数据类型,int、uint、float
- size:每个元素的数据长度,整型长度为8、16、32、64,浮点型为32。
- num:元素个数,在NEON中,每个寄存器都是64位或者128位,即size与num的乘积必须为64或128。
比如uint32x4_t为由4个32位无符号整型组成的128位寄存器,float32x2_t为由4个32位浮点数组成的64位寄存器。
操作函数:
NEON指令的一般格式为:
v op dt_type。其中:
- v:NEON函数的标记符;
- op:操作,add、sub、and等;
- dt:表示所操作寄存器等长度,当寄存器为64位,dt为空;当寄存器为128位,dt为q;
- type:对应数据类型的缩写,比如u8(uint8)、s16(int16)、f32(float32)。
Neon支持加减乘除、比较大小、左移右移、绝对值、加载保存数值、拆分、组合等操作。
例如,将两个uint8x16_t的寄存器相加,最终返回一个uint8x16_t的寄存器,函数原型如下:
uint8x16_t vaddq_u8 (uint8x16_t __a, uint8x16_t __b);
下面再给出几个常用的函数:
int8x8_t vsub_s8 (int8x8_t __a, int8x8_t __b);
//减法,ri = ai - bi
int32x2_t vld1_s32 (const int32_t * __a);
//从内存a取出数据至寄存器中
void vst1_f32 (float32_t * __a, float32x2_t __b);
//把寄存器b中的数据存入内存a中
int16x4_t vdup_n_s16 (int16_t __a);
//将寄存器中的数据初始化为常数,ri = a
3、简单例子
那么接下来,我们直接给出一个例子,来看看NEON是如何进行并行优化的:
#include <opencv2/opencv.hpp>
#include<iostream>
#include<pthread.h>
#include <ctime>
using namespace std;
using namespace cv;
int main()
{
/*
普通的for循环
*/
clock_t startTime,endTime;
startTime = clock();//计时开始
for(int m=0; m<10000; m++){
short num[8] = {1,2,3,4,5,6,7,8};
for(int i=0; i<8; i++){
num[i] += 12;
}
}
endTime = clock();//计时结束
cout << "The run time without neon is: \t" <<(double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
/*
使用NEON指令集
*/
startTime = clock();//计时开始
for(int m=0; m<10000; m++){
short num[8] = {1,2,3,4,5,6,7,8};
int16x8_t v0,v1;
v0 = vld1q_s16(num); //将数组num中的数存入NEON寄存器v0
v1 = vdupq_n_s16(12); //将8个常数12存入NEON寄存器v1
v0 = vaddq_s16(v0, v1); //加法操作
vst1q_s16(num, v0); //将NEON寄存器v0的值存回数组num中
}
endTime = clock();//计时结束
cout << "The run time with neon is: \t" <<(double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
return 0;
}
输出结果:
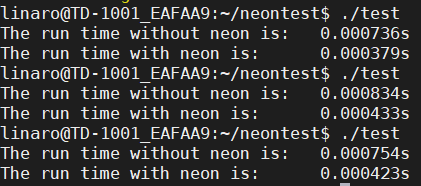
可以看到在简单的for循环中使用NEON进行并行优化,运行速度有了大幅度提升。
由于OpenCV环境里内置了NEON指令集,只需要在搭建了OpenCV的环境下引用头文件<opencv2/opencv.hpp>即可使用NEON指令集。
如果需要查找NEON函数,可以参考以下知乎链接、官网或者电子书。
同时,OpenCV源码里对NEON指令集又进行了一层封装,也有了更多功能的函数可以使用,封装好的NEON函数和数据类型可以在OpenCV官网中查找到。
二、OpenCV环境配置
这次的实验环境为搭载了ubuntu系统的RK3399的嵌入式开发板,我需要先通过远程连接到开发板的操作系统,在操作系统中安装好OpenCV的环境并打开NEON指令集。
远程连接主要使用WinSCP和MobaXterm两个软件,下面简单介绍一下它的用法:
WinSCP:
它的主要功能是在本地与远程计算机间安全的复制文件,支持与其它系统,比如linux系统的连接。
登录后即可查看到远程计算机中的文件,并进行传输等操作。
MobaXterm:
它也是一个远程连接工具,单击左上角的Session按钮,选择SSH选项并填写相关信息进行登录,登录后可以就看到控制台界面和图形化界面,并在上面进行操作了。

远程连接到开发板上,接下来开始搭建OpenCV环境。
1、安装依赖包
使用sudo apt-get install命令安装cmake和所需依赖包,代码如下:
sudo apt-get install cmake
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff4.dev libswscale-dev libjasper-dev
安装依赖包的过程中,发现libjasper-dev依赖包无法成功安装,报错为:
errorE: unable to locate libjasper-dev
解决方法是安装另一个依赖包,命令如下,其中libjasper1是libjasper-dev的依赖包:
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt update
sudo apt install libjasper1 libjasper-dev
2、下载OpenCV库
OpenCV库只需要到官网下载即可,这里我们选择了OpenCV4.0.0版本,下载其source版本;在Ubuntu系统上,也可以使用命令下载:
git clone https://github.com/Itseez/opencv.git
git clone https://github.com/Itseez/opencv_contrib.git
如果是直接通过官网下载,得到压缩文件后复制到准备安装的目录中,解压,进入opencv目录,开始下一步操作。
3、编译、执行
在opencv目录中,我们先执行mkdir build命令创建一个编译文件夹build,进入编译文件夹中,cmake一下。
cmake -D CMAKE_INSTALL_PREFIX=/usr/local -D CMAKE_BUILD_TYPE=Release -D OPENCV_EXTRA_MODULES_PATH=/opencv_contrib/modules ..
接下来是耗时最长的步骤,执行编译(-j4是同时进行四线程操作,可以加速编译):
sudo make -j4
编译完成后是这样的——
编译完成后,执行安装命令:
sudo make install
安装完成后是这样的——
执行完毕后,OpenCV编译过程就结束了。
4、配置环境
接下来就需要配置一些OpenCV的编译环境,首先将OpenCV库添加到路径,从而可以让系统找到。利用文本编辑器打开以下文件,在开发板上直接使用vim打开:
sudo vim /etc/ld.so.conf.d/opencv.conf
打开后在文件末尾添加:/usr/local/lib (vim的操作可以参考vim常用命令总结)
然后输入命令:
sudo /bin/bash -c 'echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf'
sudo ldconfig
然后,还需要为程序指定OpenCV头文件位置,这里使用pkg-config命令来完成。首先在 /etc/profile 中添加export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
sudo vim /etc/profile
# 在末尾添加export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
安装完毕之后验证版本看是否安装成功:
pkg-config --modversion opencv
5、测试
最后我们可以新建一个程序测试下:
首先建立一个文件夹OpenCV_Code,在文件夹内新建一个cpp文件,名为test.cpp。
#include <stdio.h>
#include <opencv2/opencv.hpp>
using namespace cv;
int main(int argc, char** argv )
{
if ( argc != 2 )
{
printf("usage: DisplayImage.out <Image_Path>\n");
return -1;
}
Mat image;
image = imread( argv[1], 1 );
if ( !image.data )
{
printf("No image data \n");
return -1;
}
namedWindow("Display Image", WINDOW_AUTOSIZE );
imshow("Display Image", image);
waitKey(0);
return 0;
}
再此文件夹下继续新建一个文件,名为 CMakeLists.txt:
cmake_minimum_required(VERSION 2.8)
project( test )
find_package( OpenCV REQUIRED )
add_executable( test test.cpp )
target_link_libraries( test ${OpenCV_LIBS} )
之后在此文件夹下命令行执行:
cmake .
make
此时OpenCV_Code文件夹中已经产生了可执行文件test,找一张图片命名为t.jpg放在OpenCV_Code下,运行:
./test t.jpg
如果弹出窗口显示图片,那么我们的OpenCV环境配置成功。
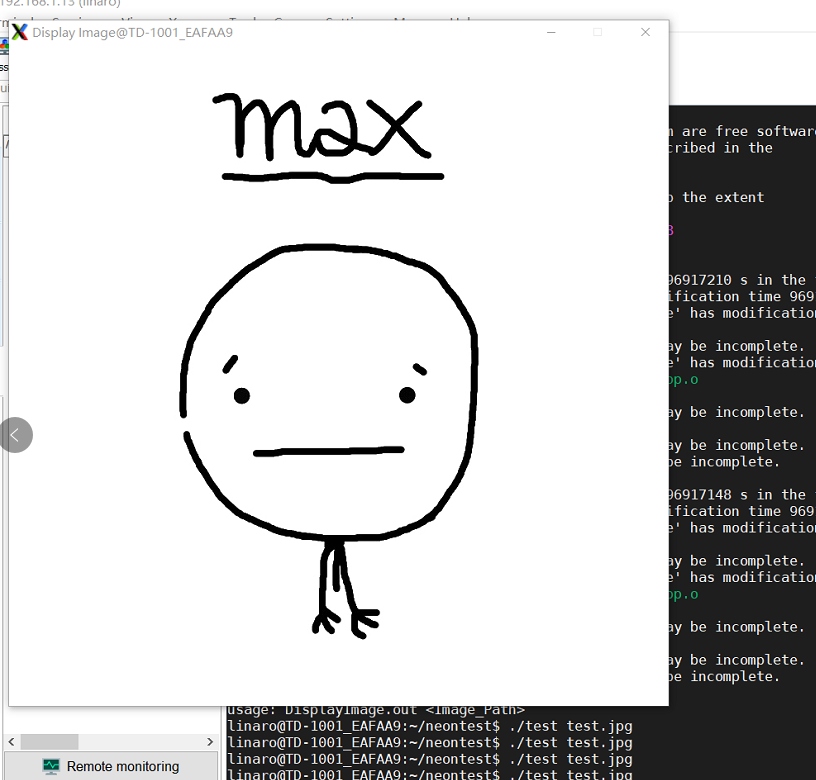
同样,我们可以测试NEON指令集是否打开,将cpp代码修改为上面给出的NEON例子,重新执行make和./test指令,如果成功运行,说明NEON指令集已经打开。
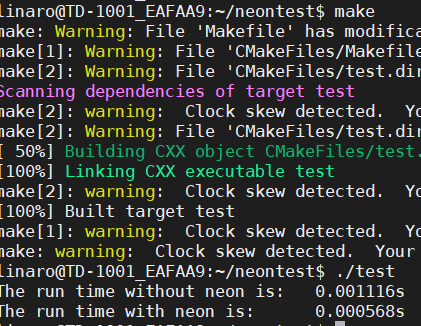
在实际配置环境的时候我还是花了不少时间,在配置时遇到了存储空间不足、操作权限不够等问题,在长时间的编译那一步时,有时还因为和开发板的连接中断而需要重来。最后在师兄的帮助下成功完成了环境配置,开始代码优化和测试。
三、OpenCV源码
这次需要修改的OpenCV源码,是在双目匹配的图像校正步骤中使用到的remap函数。简单来说,在执行remap函数之前,我们已经通过计算得到了关于图像的一个映射,remap函数是将映射应用到实际图像上的一步操作。
可以想象,根据一个函数对一幅图像进行映射,里面一定涉及大量重复的计算操作(例如在一个区域内对每一个像素点进行统一的操作),代码中重复计算的部分可以使用NEON进行优化提速。
对remap函数和相关步骤更细致的介绍可以看我的这篇博文里图像矫正的那部分。
1、修改内容
remap函数定义的位置为opencv-4.0.0\modules\imgproc\src\imgwarp.cpp,文件中,而其中使用了一个RemapInvoker的类,这个类的括号运算符重载operator()是我们修改的目标,同样位于当前文件中。
重载函数中最外层有几个for循环,如下:
//first
short* XY = bufxy.ptr<short>(y1);
const short* sXY = m1->ptr<short>(y+y1) + x*2;
const ushort* sA = m2->ptr<ushort>(y+y1) + x;
x1 = 0;
for( ; x1 < bcols; x1++ )
{
int a = sA[x1] & (INTER_TAB_SIZE2-1);
XY[x1*2] = sXY[x1*2] + NNDeltaTab_i[a][0];
XY[x1*2+1] = sXY[x1*2+1] + NNDeltaTab_i[a][1];
}
//second
short* XY = bufxy.ptr<short>(y1);
const float* sX = m1->ptr<float>(y+y1) + x;
const float* sY = m2->ptr<float>(y+y1) + x;
x1 = 0;
for( ; x1 < bcols; x1++ )
{
XY[x1*2] = saturate_cast<short>(sX[x1]);
XY[x1*2+1] = saturate_cast<short>(sY[x1]);
}
//third
bufxy = (*m1)(Rect(x, y, bcols, brows));
const ushort* sA = m2->ptr<ushort>(y+y1) + x;
x1 = 0;
for( ; x1 < bcols; x1++ ){
A[x1] = (ushort)(sA[x1] & (INTER_TAB_SIZE2-1));
}
//forth
const float* sX = m1->ptr<float>(y+y1) + x;
const float* sY = m2->ptr<float>(y+y1) + x;
x1 = 0;
for( ; x1 < bcols; x1++ )
{
int sx = cvRound(sX[x1]*INTER_TAB_SIZE);
int sy = cvRound(sY[x1]*INTER_TAB_SIZE);
int v = (sy & (INTER_TAB_SIZE-1))*INTER_TAB_SIZE + (sx & (INTER_TAB_SIZE-1));
XY[x1*2] = saturate_cast<short>(sx >> INTER_BITS);
XY[x1*2+1] = saturate_cast<short>(sy >> INTER_BITS);
A[x1] = (ushort)v;
}
//fifth
const float* sXY = m1->ptr<float>(y+y1) + x*2;
x1 = 0;
for( ; x1 < bcols; x1++ )
{
int sx = cvRound(sXY[x1*2]*INTER_TAB_SIZE);
int sy = cvRound(sXY[x1*2+1]*INTER_TAB_SIZE);
int v = (sy & (INTER_TAB_SIZE-1))*INTER_TAB_SIZE + (sx & (INTER_TAB_SIZE-1));
XY[x1*2] = saturate_cast<short>(sx >> INTER_BITS);
XY[x1*2+1] = saturate_cast<short>(sy >> INTER_BITS);
A[x1] = (ushort)v;
}
2、使用NEON进行修改
在后来对函数的分析的时候,发现外层的for循环有几个已经在源码中进行了NEON优化,最后决定尝试对还没被优化过的第一个循环进行优化:
//first
short* XY = bufxy.ptr<short>(y1);
const short* sXY = m1->ptr<short>(y+y1) + x*2;
const ushort* sA = m2->ptr<ushort>(y+y1) + x;
x1 = 0;
for( ; x1 < bcols; x1++ )
{
int a = sA[x1] & (INTER_TAB_SIZE2-1);
XY[x1*2] = sXY[x1*2] + NNDeltaTab_i[a][0];
XY[x1*2+1] = sXY[x1*2+1] + NNDeltaTab_i[a][1];
}
优化的第一步是先确认各个变量对应的数据类型,这里有sA、XY、sXY、NNDeltaTab_i三个数组,经过查找,得到它们的数据类型:
static uchar NNDeltaTab_i[INTER_TAB_SIZE2][2] //8位x16个
const ushort* sA //16位x8个
short* XY //16位x8个
const short* sXY //16位x8个
那么,我们暂定在每一次循环中同时处理16个数据。已知在原来for循环中,循环次数为bcol次,那我们将其对16取余,对这部分进行原来的循环处理,剩下的次数为16的整数倍,使用NEON函数进行处理。那么得到一个函数框架:
//执行NEON优化的条件编译
#if CV_SIMD128
int mod = bcols % 16;
//取余
for( ; x1 < mod; x1++ )
{
int a = sA[x1] & (INTER_TAB_SIZE2-1);
XY[x1*2] = sXY[x1*2] + NNDeltaTab_i[a][0];
XY[x1*2+1] = sXY[x1*2+1] + NNDeltaTab_i[a][1];
}
//先处理所余次数
for( ; x1 < bcols; x1+=16 ){
/*
code
*/
}
//剩下的每16次一循环进行处理
#endif
接下来依次分析每一句代码:
int a = sA[x1] & (INTER_TAB_SIZE2-1)的实现比较简单,每次将sA的连续8个元素取出,和常数INTER_TAB_SIZE2-1相与即可。
XY[x1*2] = sXY[x1*2] + NNDeltaTab_i[a][0]和 XY[x1*2+1] = sXY[x1*2+1] + NNDeltaTab_i[a][1]的实现是一个难点,得到的变量a是作为NNDeltaTab_i的地址使用,这样导致访问的数据不是连续的。在上面对NEON的介绍中,我们也知道NEON更多的是对地址连续的数据进行并行操作。我们需要找到方法去实现对不连续地址的同时操作。
另外,对sXY、XY的存取也是间隔的,这也需要找到方法去实现。
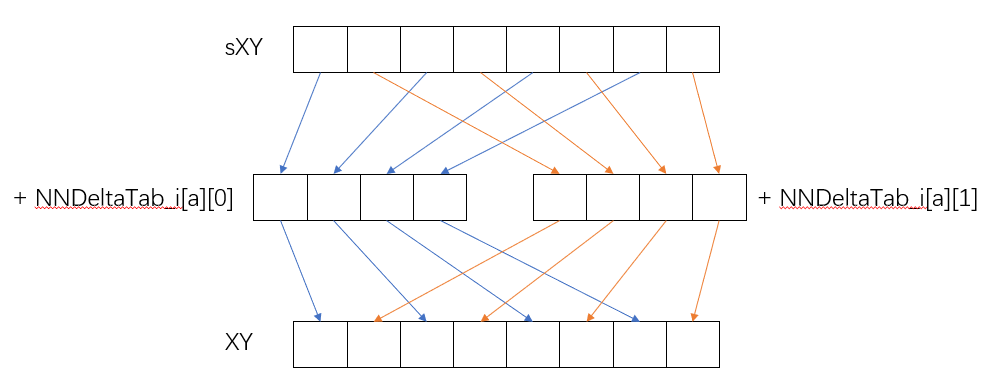
为此,我们找到了三个OpenCV封装的NEON函数,可以解决这两个问题:
(1)v_lut():
这个函数可以实现对不连续地址的一次性操作,函数原型如下(这里以int32x4的数据类型说明):
v_int32x4 v_lut(const int* tab, const v_int32x4& idxvec)
{
int CV_DECL_ALIGNED(32) elems[4] =
{
tab[vgetq_lane_s32(idxvec.val, 0)],
tab[vgetq_lane_s32(idxvec.val, 1)],
tab[vgetq_lane_s32(idxvec.val, 2)],
tab[vgetq_lane_s32(idxvec.val, 3)]
};
return v_int32x4(vld1q_s32(elems));
}
可以看到,idxvec为存储了地址的int32x4寄存器,tab为待读取的内存空间;这里每次都用vgetq_lane_s32()取出一个元素,作为tab的地址进行读取,最后将结果存至一个int32x4的寄存器中返回。
而由于NNDeltaTab_i[][]是一个二维数组,在代码测试中发现没有与其数据类型相匹配的函数,于是我们仿照v_lut函数的实现方式,补充了一个内联函数,并将内存减少为8个字节对齐:
inline v_int8x16 v_lut_X(
const uchar Tab[][2],
const v_uint16x8& v0,
const v_uint16x8& v2,
const int N)
{
int8_t CV_DECL_ALIGNED(8) elems[16] =
{
Tab[vgetq_lane_u16(v0.val, 0)][N],
Tab[vgetq_lane_u16(v0.val, 1)][N],
Tab[vgetq_lane_u16(v0.val, 2)][N],
Tab[vgetq_lane_u16(v0.val, 3)][N],
Tab[vgetq_lane_u16(v0.val, 4)][N],
Tab[vgetq_lane_u16(v0.val, 5)][N],
Tab[vgetq_lane_u16(v0.val, 6)][N],
Tab[vgetq_lane_u16(v0.val, 7)][N],
Tab[vgetq_lane_u16(v2.val, 0)][N],
Tab[vgetq_lane_u16(v2.val, 1)][N],
Tab[vgetq_lane_u16(v2.val, 2)][N],
Tab[vgetq_lane_u16(v2.val, 3)][N],
Tab[vgetq_lane_u16(v2.val, 4)][N],
Tab[vgetq_lane_u16(v2.val, 5)][N],
Tab[vgetq_lane_u16(v2.val, 6)][N],
Tab[vgetq_lane_u16(v2.val, 7)][N]
};
return v_int8x16(vld1q_s8(elems));
}
(2)v_load_deinterleave():
这个函数从内存中的数据间隔取出到两个寄存器中:
mem{A1 B1 A2 B2 …} ==> reg{A1 A2 …}, reg{B1 B2 …}
函数原型如下:
void v_load_deinterleave(
const _Tp* ptr,
v_reg<_Tp, n>& a,
v_reg<_Tp, n>& b
)
{
int i, i2;
for( i = i2 = 0; i < n; i++, i2 += 2 )
{
a.s[i] = ptr[i2];
b.s[i] = ptr[i2+1];
}
}
ptr指向内存首地址,a、b为两个数据类型相同的寄存器。
(3)v_store_interleave():
同样的,这个函数将两个寄存器的元素间隔存入内存中:
reg{A1 A2 …}, reg{B1 B2 …} ==> mem{A1 B1 A2 B2 …}
函数原型如下:
void v_store_interleave(
_Tp* ptr,
const v_reg<_Tp, n>& a,
const v_reg<_Tp, n>& b,
hal::StoreMode = hal::STORE_UNALIGNED
)
{
int i, i2;
for( i = i2 = 0; i < n; i++, i2 += 2 )
{
ptr[i2] = a.s[i];
ptr[i2+1] = b.s[i];
}
}
ptr指向内存首地址,a、b为两个数据类型相同的寄存器。
除此之外,我们还需要一个函数将一个int8x16的寄存器拆分成两个int16x8的寄存器,利用以下函数即可:
(4)v_expand():
这个函数实现的拆分功能如下:
reg{A B C D} ==> reg{A B}, reg{C D}
void v_expand(
const v_reg<_Tp, n>& a,
v_reg<typename V_TypeTraits<_Tp>::w_type, n/2>& b0,
v_reg<typename V_TypeTraits<_Tp>::w_type, n/2>& b1
)
{
for( int i = 0; i < (n/2); i++ )
{
b0.s[i] = a.s[i];
b1.s[i] = a.s[i+(n/2)];
}
}
这里只需要注意寄存器a、b0、b1的数据类型匹配。
3、修改结果
使用以上函数,再加上几个普通的运算函数(因为OpenCV的NEON数据类型进行了运算符重载,可以直接使用运算符进行计算),在上面的框架下进行补充修改,最终结果如下:
#if CV_SIMD128
int mod = bcols % 16;
for( ; x1 < mod; x1++ )
{
int a = sA[x1] & (INTER_TAB_SIZE2-1);
XY[x1*2] = sXY[x1*2] + NNDeltaTab_i[a][0];
XY[x1*2+1] = sXY[x1*2+1] + NNDeltaTab_i[a][1];
}
v_uint16x8 v = v_setall_u16(INTER_TAB_SIZE2-1);
//初始化常量
for( ; x1 < bcols; x1+=16 ){
v_uint16x8 v0 = v_load(sA + x1);
v0 = v0 & v;//对应int a = sA[x1] & (INTER_TAB_SIZE2-1);
v_uint16x8 v2 = v_load(sA + x1 + 8);
v2 = v2 & v;//对应int a = sA[x1] & (INTER_TAB_SIZE2-1);
v_int16x8 vX1,vY1;
v_load_deinterleave(sXY + x1 * 2, vX1, vY1);//间隔取出sXY
v_int16x8 vX2,vY2;
v_load_deinterleave(sXY + (x1 + 8) * 2, vX2, vY2);//间隔取出sXY
v_int8x16 temp1 = v_lut_X(NNDeltaTab_i,v0,v2,0);
v_int16x8 tX1,tX2;
v_expand(temp1, tX1, tX2);//8x16 => 16x8 + 16x8
tX1 = tX1 + vX1;
tX2 = tX2 + vX2;//对应sXY[x1*2] + NNDeltaTab_i[a][0];
v_int8x16 temp2 = v_lut_X(NNDeltaTab_i,v0,v2,1);
v_int16x8 tY1,tY2;
v_expand(temp2, tY1, tY2);//8x16 => 16x8 + 16x8
tY1 = tY1 + vY1;
tY2 = tY2 + vY2;//对应sXY[x1*2+1] + NNDeltaTab_i[a][1];
v_store_interleave(XY + x1 * 2, tX1, tY1);//存回XY
v_store_interleave(XY + (x1 + 8) * 2, tX2, tY2);//存回XY
}
#endif
修改后进入opencv-4.0.0/build目录,执行命令sudo make -j4 && sudo make install重新编译,完成后可以使用程序测试修改结果。
4、测试程序
测试程序由师兄编写,完成了从左右图像生成深度图的整个过程:
其中的stereoRectify.cpp文件调用了remap()函数,将其进行修改,加上计时输出,然后分别在开启NEON前、开启NEON后运行测试:
void StereoRectify::rectify(cv::Mat left_src, cv::Mat right_src, cv::Mat &left_dst, cv::Mat &right_dst)
{
for(int i=0;i<5;i++){//5次计时
time_t t1 = cv::getTickCount();//计时起点
for(int i=0;i<500;i++){//500x2次remap
remap(left_src, left_dst, calib_para.rmap[0][0], calib_para.rmap[0][1], cv::INTER_NEAREST , cv::BORDER_REPLICATE);
remap(right_src, right_dst, calib_para.rmap[1][0], calib_para.rmap[1][1], cv::INTER_NEAREST , cv::BORDER_REPLICATE);
}
time_t t2 = cv::getTickCount();//计时终点
cout << "cost " << (t2 - t1) * 1000/cv::getTickFrequency()/500<<" ms" << endl;//计时结果输出
}
}
开启NEON前:
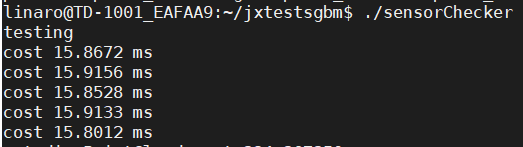
开启NEON后:
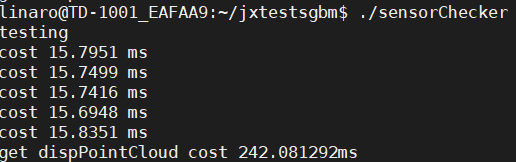
虽然速度成功提升了,不过只有一点微弱的提升。得到这个结果之后,我们对remap函数再次进行了分析,发现其中括号运算符重载operator()的确是运行时间占比较高的一部分,不过我们修改的那部分在其中花费的时间是比较少的,所以速度提升的效果并不明显。
后记
这几个星期接触了很多新鲜的东西,也遇到了很多的困难,为了解决问题花了不少时间去查资料、问师兄。很感谢几位师兄在我们遇到问题的时候都很热心地为我们解答,特别是jx师兄在优化任务的时候全程带我,在配置OpenCV环境、最后的代码优化都给了我很多解答和建议。
这段时间还是学到了很多的东西,从一开始对双目匹配流程的大概理解,到后面细致地去了解图像校正这一步骤,学着分析OpenCV的源码并使用NEON进行修改,还有远程连接开发板并进行操作,很大一部分都是之前没有接触过的。
不过最后得到的优化结果还是有点不尽人意,由于在优化时走了不少弯路,最后发现优化效果不明显的原因的时候时间已经比较晚了,没有时间把另一部分的代码再进行分析和优化,这也有点遗憾。